Next: C++プログラミングを始めよう Up: C++プログラミング入門 Previous: C++プログラミング入門 索引
プログラムは問題やタスクを解決するために書かれることが多い。そこで,次のような問題を考えてみる。ある本屋では,売れた本のタイトルと出版社を帳簿につけている。また,この情報は本が売れた順に入力される。この本屋の主人は2週間おきにタイトルごとに何冊売れたかと,出版社ごとに何冊売れたかを分類している。このとき作成したリストは出版社名ごとにアルファベット順に整理し,本の再注文に役立てている。この本屋の主人が,これらのことを行ってくれるプログラムを書いてくれと頼んできたとする。
| タイトル | 出版社 |
| 応用数学入門 | 開成出版 |
| C++入門 | ASCII |
| わかる統計学 | 森北出版 |
| C++入門 | 開成出版 |
| 微分積分学 | 森北出版 |
| 応用数学入門 | 開成出版 |
| 数値解析入門I | 開成出版 |
| C++入門 | ASCII |
| 微分積分学 | 森北出版 |
| 応用数学入門 | 開成出版 |
| 数値解析入門I | 開成出版 |
| 微分積分学 | 森北出版 |
| 応用数学入門 | 開成出版 |
| C++入門 | 開成出版 |
| タイトル | 冊数 |
| 応用数学入門 | 4 |
| わかる統計学 | 1 |
| C++入門 | 4 |
| 微分積分学 | 3 |
| 数値解析入門I | 2 |
| 出版社 | 冊数 |
| 開成出版 | 8 |
| ASCII | 2 |
| 森北出版 | 4 |
問題を解決するための一つの方法は,大きな問題を小さな問題の集まりに分割していくことである。できれば,これらの小さな問題は簡単に解決でき,またまとめることが簡単で大きな問題を解決できることが望ましい。もし,分割した問題が大きすぎて解決できないならば,もっと小さな問題に分割する必要がある。このようにして分割された問題の一つ一つが解決できるまで分割を行う。この方法は分割統治法(divide and conquer method)とよばれている。この方法を用いて本屋の問題を解決しよう。そのためには主人の行動を一つ一つ分析していく必要がある。
まず,本屋の主人は売り上げごとに帳簿を分類している。ということは,帳簿を読まなくてはならない。そこで,帳簿を読むというプログラムが必要となる。次に,帳簿を分類するために,タイトルごとの売り上げ冊数と出版社ごとの売り上げ冊数を数えるというプログラムが必要になる。さらに,本屋の主人は作成したリストを出版社名ごとにアルファベット順に整理しているので,このことを行うプログラムが必要になる。最後に,このようにしてできたリストが再注文で必要になるので,結果を打ち出す必要がある。これより,次の4つの副プログラムに分割できる。
ここで,プログラミングを少し学べば,1.2.と4.はどう解決すればよいか分かる問題である。つまり,これ以上分割する必要がない問題である。ところが3.に関してはこのままではどうやればよいのかよく分からない。そこでもう一度分割統治法を適用する。
3a,3b,3cはこれで解決法が分かる問題になった。これにより,全ての副プログラムの解決法が分かったので,元の問題を解決することができることになる。さらに,もともとの問題解決の順序は正しくないことも分かった。解決順は次のようになるべきである。
この一連の手順をアルゴリズム(algorithm)という。次のステップはこのアルゴリズムを特定のプログラミング言語(ここではC++)に変換することである。
C++プログラム
C++では,何々に等しいとか何々をするというアクションは式(expression)として扱われる。セミコロンで終了する式は式文(statement)または命令文とよばれる。以下のものはC++の式文である。
|
int book_count = 0;
book_count = books_on_shelf + books_on_order; cout << "the value of book_count: " << book_count; |
最初の式文は宣言文(declaration)で,book_countは識別子(identifier)とよばれる。この式文はコンピュータの記憶領域にbook_countという名前に対応した整数値を格納する場所を確保する。0はリテラル定数(数値の定数)である。book_countは初期値が0となるように初期化されている。
2つ目の文は代入文である。これによりbook_countに対応するコンピュータの記憶領域に,books_on_shelfとbooks_on_orderを加えた結果を格納する。このとき,books_on_shelfとbooks_on_orderは整数型の変数ですでに値が代入されているものとする。
3つ目の文は出力文である。coutはユーザの画面への出力を意味する。<<
は出力用の演算子である。画面へは,最初に2重引用符で囲まれた文字列リテラルが出力され,次にbook_countという名前に対応するコンピュータの記憶領域に格納された値が出力される。したがって,この式文の出力は
|
the value of book_count: 11273
|
式文は関数とよばれる1つのまとまりとして論理的にまとめられる。例えば,売り上げを読む文はread()とよばれる一つのまとまりにまとめることができる。同様にして,整列をsort(),重複したタイトルはcompact()に,そして書き込みをprint()関数にまとめることができる。
全てのC++プログラムはプログラムを走らせるまえに,main()関数を1つ含んでいなければならない。このアルゴリズムのmain()関数は次のように定義することができる。
| int main()
{ read(); sort(); compact(); print(); return 0; } |
C++プログラムはmain()関数の最初の命令文から実行する。この場合,関数read()が最初に実行される。プログラムはmain()関数の中では上から順に実行される(順接)。プログラムは一般にmain()関数の最後の行を実行すると終了する。
関数は4つの部分から構成されている。それらは戻り値の型,関数名,引数のリスト,関数本体である。最初の3つはまとめて関数のプロトタイプとよばれる。関数本体は中括弧{から}までで,その間にはプログラムが入る。
この関数の場合,main()関数の本体は関数read(), sort(), compact(), print()を呼び出す。これらが終了すると,式文
return 0;
が実行される。標準C++では,式文 return 0;がないときには,ディフォルトで0を返すことになっている。
さて,ここでプログラムがどのように実行可能になるか見ていこう。最初に,関数read(), sort(), compact(), print()の定義を行う必要がある。ここでは,次のような試作例で十分である。
| void read() {cout << "read()\n";}
void sort() {cout << "sort()\n";} void compact() {cout << "compact()\n";} void print() {cout << "print()\n";} |
このように,徐々にプログラムを完成させていく方法は,避けて通れないプログラミングエラーを制御する尺度を与えれくれる。一度にプログラムを走るようにすることはあまりにも複雑で難解なことである。
プログラムのソースファイル名は一般に二つの部分からできている。一つはファイル名でもう一つは拡張子である。拡張子はファイルの中身が識別できるような名前になっている。例えば,
bookstore.c
は慣例で,Cのプログラムテキストファイルである。C++のプログラムテキストファイルは慣例で
bookstore.cpp または bookstore.c**
のように表す。
テキストエディタを用いて次のプログラムを書いてみる。
|
#include <iostream>
using namespace std; void read(); void sort(); void compact(); void print(); int main() { read(); sort(); compact(); print(); return 0; } |
iostreamは入出力ストリームライブラリの標準ヘッダファイルである。これは,coutについての情報を持っている。#includeは前処理句(preprocessor directive)であり,iostreamの内容をテキストファイルへ読み込む働きをしている。
C++の標準ライブラリで定義されている名前,例えばcout,は
|
#include <iostrem>
|
|
#include <using namespace std;
|
プログラムを打ち終えたら,prog1.cppという名前をつけて保存しよう。次に,C++のコンパイラを用いてコンパイルしてみる。どのようにコンパイルするかは用いているコンパイラにより異なるので,例題1.1を参照。
コンパイラの仕事の一つはプログラムのテキストが正確かを解析することである。コンパイラはプログラムの意味は理解できないが,プログラムの構文については間違いを見つけることができる。よくある二つのプログラムエラーは次のようなものである。
構文エラーとは,例えば次のようなものである。
|
int main( //)がない
{ read(): // 違法文字 ':' sort(); compact(); print(); return 0 // ';'が足りない } |
型エラーとは,用いる変数の型に応じて型を宣言しなければならないのに,間違った型を宣言してしまったりすることをいう。
エラーメッセージは一般に式番号とコンパイラがたどりついた簡単なエラーの発生理由を含んでいる。エラーは発生順に訂正する習慣を身に着けるべきである。エラーの修正が済んだらまたコンパイルする。このステップはエディットーコンパイルーデバッグとよばれる。
コンパイラの仕事のもう一つの役割は,コード生成とよばれるコンピュータに分かる命令テキストにプログラムを変換することである。
コンパイルがうまくいくと実行ファイルが作られる。この実行プログラムを起動すると私たちのプログラムの場合次のような出力を表示する。
|
read()
sort() compact() print() |
C++には基本のデータ型(整数型,浮動小数点型,文字型,ブール型)が含まれている。C++標準ライブラリには文字列,複素数,ベクタ,リストなど基本データ型の拡張されたものも含まれている。例えば,文字列は
|
#include<string>
string current_chapter = "C++プログラミングを始めよう"; |
|
#include<vector>
vector<string%gt; chapter_tilte(20); |
どのコンピュータ言語や標準ライブラリも全てのデータ型を用意していることはありえない。近代的なコンピュータ言語では,むしろ新しいデータ型を作るための道具が用意されている。C++ではその道具として,クラスというメカニズムが用意されている。文字列,複素数,ベクタ,リストなどはC++でプログラムされたクラスである。クラスについては,10章で学ぶ。
プログラムの流れと制御
デフォルトでは,プログラムは上から順に実行される。つまり本屋の問題では,まずread()が実行され,つぎにsort(),compact(),print()と続く。しかし,本があまり売れなかった場合,sort()やcompact()関数を実行することにあまり意味がない。そこで,条件文ifを用いて次のように書くことができる。
|
#include<iostream>
using namespace std; int read(); // 読み込んだ本の冊数を返すとする void sort(); void compact(); void print(); int main() { int count = read(); if(count > 1){ sort(); compact(); } if(count == 0){ cout << "今月は売り上げ零$\yen$n"; } else { print(); } return 0; } |
最初のif文は括弧の中が正しければ{から}までを実行するという条件実行である。つぎのif文には2つの実行枝がある。もし括弧内が正しければ,今月は売り上げ零と出力し,そうでなければ,print()関数を呼び出す。if文については3章で詳しく紹介する。
二つ目の順序通りでない式文は反復である。反復ではある条件が満たされている間,一つまたは二つ以上の式文が実行される。例えば,
|
int main()
{ int iteration = 0; bool continue_loop = true; while(continue_loop != false){ iterations++; cout << "while loop は" << iterations << "回実行された"; if(iterations == 5){ coutinue_loop = false; } } return 0; } |
において,whileループがiterationsが5に等しくなりcontinue_loopにfalseが代入されるまで5回繰り返される。式文
iterations++;
はiterationsの値を1ずつ増やす。whileループに関しては4章で詳しく説明している。
前処理句
前処理句#includeはファイル名の内容を読みなさいというコンパイラに対する命令であり,次のどちらかの形をとる。
|
#include<some_file.h>
#include "my_file.h" |
入力と出力
C++では,入力と出力は入出力ストリームライブラリ(iostream library)によって提供されている。入出力ストリームライブラリは標準ライブラリの一つで,オブジェクト指向クラス階層としてC++に搭載されている。
画面からの入力は標準入力(standard input)といわれ,入出力オブジェクトcinと結び付いている。画面への出力は標準出力(standard output)といわれ,入出力オブジェクトcoutと結び付いている。もう一つの入出力オブジェクトで画面と結びついているものはcerrで標準エラーといわれる。
入出力ストリームライブラリを必要とする全てのプログラムは,次のヘッダファイルを必要とする
|
#include <iostream>
|
出力演算子 <<
は標準出力へ値を出力するのに用いることができる。例えば,
|
int v = 2, w = 3;
cout << v << "と" << w << "の和は" << v+w << endl; |
|
2と3の値の和は5
|
入力演算子(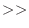 )は標準入力から値を読むのに用いることができる。例えば,
)は標準入力から値を読むのに用いることができる。例えば,
|
string file_name;
cout << "ファイルの名前を入力して下さい"; cin >> file_name; |
ファイルの入出力
iostreamライブラリはファイルの入力と出力もサポートしている。標準入出力に用いることができる演算子は,入出力ように開かれたファイルにも用いることができる。入力または出力用にファイルを開くにはiostreamのヘッダファイルの他に次のヘッダファイルを用意しなければならない。
|
#include<fsream>
|
出力用にファイルを開くには,ofstream型のオブジェクトを宣言する。
|
ofstream outfile("ファイル名");
|
ファイルが正しく開かれたかをテストするには
|
if(!outfile){
cerr << "ファイルを開くことができません" << endl; } |
同様に,入力用にファイルを開くには,ifstream型のオブジェクトを宣言する。
|
ifstream infile("ファイル名");
if(!infile){ cerr << "ファイルを開くことができません" << endl; } |
次のプログラムはin_fileという名前のファイルを読み込み,ファイルの中の全ての言葉をout_fileという名前のファイルに空白をつけて書き出す。
|
#include <iostream>
#include <fstream> #include <string> int main() { ofstream outfile("out_file"); ifstream infile("in_file"); if(!infile){ cerr << "ファイルを開くことができません;\n"; return -1; } if(!outfile){ cerr << "ファイルを開くことができません;\n"; return -2; } string word; while(infile >> word){ outfile << word << ' '; return 0; } |
これでなんとなくC++言語は私たちにどんなものを提供してくれるのか分かって貰えただろうか。この後,私たちに必要なことは,クラスやテンプレートを用いて新しい型を構築していくことである。