Next: 選択(selection) Up: C++プログラミング入門 Previous: C++プログラミングを始めよう 目次 索引
「キーワード」はC++コンパイラに対して,データ型や命令文の意味を持ち,ユーザはこれを識別子としては使えない.C++のキーワードには以下のものがある.覚える必要はないが,さっと目を通しておくとよい.
| and | and_eq | asm | auto | bitand |
| bitor | bool | break | case | catch |
| char | class | compl | const | const_cast |
| continue | default | delete | do | double |
| dynamic_cast | else | enum | explict | export |
| extern | dfalse | float | for | friend |
| goto | if | inline | int | long |
| mutable | namespace | new | not | not_eq |
| operator | or | or_eq | private | protected |
| public | register | reinterpret_cast | return | short |
| signed | sizeof | static | static_cast | struct |
| switch | template | this | throw | true |
| try | typedef | typeid | typename | using |
| union | unsigned | virtual | void | volatile |
| wchar_t | while | xor | xor_eq |
「識別子」はユーザが「クラス」「変数(メンバ変数)」「メソッド(メンバ関数)」につける名前である.名前には「文字」「数字」「_」「$」が使えるが,キーワードと同じ名前は使えない.また,名前の先頭文字には「数字」,「_」は使えない. 識別子に付ける名前は慣習的に次のようになっている.
| 識別子の型 | 慣習 | 命名例 | ||||
| クラス名 |
|
|
||||
| メンバ関数名 |
|
|
||||
| メンバ変数名 | メンバ関数名と同じ. |
|
||||
| 定数 |
|
|
C++では変数を入れる箱の型を決める必要がある.箱の型を決める前に箱の名前,つまり変数名を決めなければならない.変数名は中身にあった名前を付けるのが良いとされている.例えば,テストの回数を表す変数ならば,countやtestCountやtestTimesなどが良い名前である.
ここでは,変数testTimesがテストの回数を表すとしよう.この場合,テストの回数は1,2,3…という整数なので,整数をしまっておく箱は整数型であると宣言する.例えば,
|
int testTimes;
|
|
float test_Average;
|
| 型 | 基本型 | |||||||||||||||||||
|
このあと,例題を交えながら基本データ型について細かく見ていく.
論理型はfalseまたはtrueの2値しかとることができないときに用いる.
| #include <iostream> |
| using namespace std; |
| int main( ) |
| { |
| bool flag = false; |
| cout << "flag = " << flag << endl; |
| flag = true; |
| cout << "flag =" << flag << endl; |
| } |
解答 C++ではfalse, trueは予約語で,falseは0,trueは1がプリントされる.
実行結果
![\begin{figure}% latex2html id marker 431
\centering\includegraphics[width=9.0cm]{CPPPIC/reidai2-1.eps}
\end{figure}](img19.png)
文字型は文字'A'や桁数'8'などをあらわすときに用いる.例えば,Aという文字を文字型cに代入するときには,
| char c = 'A'; |
と書く.文字Aを変数ではなく文字型として使用するときは,アポストロフィー( ' )が必要である.アポストロフィーなしでは変数と見なされ,エラーとなる.そこで,変数と区別するためにすでに学んだリテラルを用いる.ここで, int(c) とすると, int(c)は文字AのASCIIコードである65を表す.
| #include <iostream> |
| using namespace std; |
| int main() |
| { |
| char c = 'A'; |
| cout << "c = " << c << ", int(c) = " << int(c) << endl; |
| c = 't'; |
| cout << "c = "<< c << ", int(c) = " << int(c) << endl; |
| c = '\t'; |
| cout << "c = "<< c << ", int(c) = " << int(c) << endl; |
| c = '!'; |
| cout << "c = "<< c << int(c) = "<< int(c) << endl; |
| } |
解答 文字'A'を表示せよとすると,整数65ではなく文字"A"が表示される.
実行結果
![\begin{figure}% latex2html id marker 445
\centering\includegraphics[width=9.4cm]{CPPPIC/reidai2-2.eps}
\end{figure}](img20.png)
|
練習問題 2..1
文字型
文字YのASCIIコードを出力するプログラムを作成せよ. |
C++には6個の整数型が用意されている.unsigned整数型は,記憶領域をビット配列として扱うときに便利である.しかし,正の整数を表現するためのビットを1つ増やしたいためにintの代わりにunsignedを用いるのは良くない.値を正に保つためにunsignedを宣言しても,暗黙の変換ルールにより,目的を達成することができない.
| #include <iostream>
using namespace std; int main() { int m = 65; int n = 20; cout << "m = " << m << "and n = " << n << endl; cout << "m+n =" << m+n << endl; cout << "m-n =" << m- n << endl; cout << "m*n =" << m*n << endl; cout << "m/n =" << m/n << endl; cout << "m%n =" << m%n << endl; } |
解答 たぶん注意しなければならないのは,m/nとm%nの2つであろう.mとnが整数のとき,m/nは商を表し,m%nはあまりを表す.
実行結果
![\begin{figure}% latex2html id marker 470
\centering\includegraphics[width=9.3cm]{CPPPIC/reidai2-3.eps}
\end{figure}](img21.png)
|
練習問題 2..2
整数型の演算
整数1234の末尾を消して,123を取り出すプログラムを作成せよ. |
増加と減少演算子(Increment and Decrement Operators)
++と 演算子は演算を行う数の前におくか後ろにおくかで意味が異なることに注意しよう.
演算子は演算を行う数の前におくか後ろにおくかで意味が異なることに注意しよう.
|
#include <iostream>
using namespace std; int main() { int m,n; m = 44; n = ++m; cout << "m = " << m << ", n = " << n << endl; m = 44; n = m++; cout << "m = " << m << ", n = " << n << endl; } |
解答
n = ++mは先にmの値を1増やし,それをnに代入するので前増加という.またn = m++はmの値を先にnに代入し,その後にmの値を1増やすので後増加という.
++mもm++も,ともにm = m+1のことであるが,m = m+1 とはほとんど書かないので,++と
の使い方に慣れておこう.
実行結果
![\begin{figure}% latex2html id marker 498
\centering\includegraphics[width=9.4cm]{CPPPIC/reidai2-4.eps}
\end{figure}](img23.png)
|
練習問題 2..3
増加演算子
int m=44のとき,m/++mの値はいくつになるか考え,プログラムを組んで確認せよ. |
実数を表すのに用いられる型である.
例えば10進数13.75が与えられたとする.これをコンピュータはどう扱うか見てみよう.まず,10進数13.75は2進数に変換される.
13.75 = (8+4+1) + (1/2 + 1/4) = 1101.11
次に,少数点をいちばん左まで移動する.つまり4ビットの移動を行うので,
13.75 = +0.1101112×24
書き直すと
13.75 = 01101110100002
このとき,最初の0は符号部が正であることを表し,次の6桁は少数部(仮数部)を表し,次の6桁は指数部を表す.指数の最初の数字は符号を表す.一般に32ビットの浮動少数点型では,最初の1ビットが符号部,次の23ビットが少数部,残りの8ビットが指数部を表している.ちなみに64ビットの double型では,最初の1ビットが符号部で,少数部には52ビットが割り当てられ,11ビットが指数部に割り当てられる.
浮動小数点型の算術計算は,整数型と異なり+,-,*,/の4種類で,普通の少数の計算と同じである.
|
#include <iostream>
using namespace std; int main() { double x = 125.5; double y = 20.5; cout << "x = " << x << "and y = " << y << endl; cout << "x+y =" << x+y << endl; cout << "x-y =" << x- y << endl; cout << "x*y =" << x*y << endl; cout << "x/y =" << x/y << endl; } |
実行結果
![\begin{figure}% latex2html id marker 518
\centering\includegraphics[width=9.5cm]{CPPPIC/reidai2-5.eps}
\end{figure}](img24.png)
|
練習問題 2..4
浮動小数点型の演算
3.15と42.1をキーボードから入力し,その積と商を求めるプログラムを作成せよ. |
データ型のサイズは
| sizeof(型名)
|
解答
|
#include <iostream>
using namespace std; int main() { cout << "sizeof(char) = " << sizeof(char) <<< endl; cout << "sizeof(short) = " << sizeof(short) << endl; cout << "sizeof(int) = " << sizeof(int) << endl; cout << "sizeof(long) = " << sizeof(long) << endl; cout << "sizeof(float) = " << sizeof(float) << endl; cout << "sizeof(double) = " << sizeof(double) << endl; cout << "sizeof(long double) = " << sizeof(long double) << endl; } |
実行結果
![\begin{figure}% latex2html id marker 539
\centering\includegraphics[width=9.3cm]{CPPPIC/reidai2-6.eps}
\end{figure}](img25.png)
|
練習問題 2..5
処理系のデータ型のサイズ
unsigned intのサイズを調べるプログラムを作成せよ. |
浮動小数点算術はすべてdoubleで行われるので,double型の代わりにfloatを使うときは,保管場所とアクセスタイムを気にするくらい多くの実数を使うときだけである.
C++では,charやintのような基本型の他に,自分専用のデータ型を定義することができる.その方法には10章で学ぶクラスを用いるものがあるが,ここでは,もっと簡単な方法として列挙型を考える.列挙型は次のような構文を用いる.
|
enum 列挙タグ名 {列挙型変数名}
|
例えば,列挙型Semesterを次のように定義したとする.
|
enum Semester {FALL, SPRING, SUMMER};
|
|
Semester s1, s2;
|
|
s1 = SPRING;
s2 = FALL; if (s1 == s2) cout << "同じSemester" << endl; |
列挙型はプログラムのコードを読みやすくしてくれる.ここに,いくつか特徴的な例をあげておく.
|
enum Sex {FEMALE, MALE} // 性別
enum Day {SUN, MON, TUE, WED, THU, FRI, SAT} // 曜日 enum Radix {BIN=2, OCT=8, DEC=10,HEX=16} // 基数 enum Color {RED,ORANGE, YELLOW, GREEN, BLUE, VIOLET} // 色 enum Rank {TEN,JACK, QUEEN, KING, ACE} // カード enum Suit {CLUBS, DIAMONDS, HEARTS, SPADES} // カードの組 enum Roman {I = 1, V = 5, X = 10, L = 50, C = 100, D = 500, M = 1000} // 数 |
確かに,列挙型を用いると,コードが読みやすくなるが,多用は避けるべきである.なぜなら,列挙型のリストは新たに,メンバを定義するので,例えば,Romanでは7個の文字を定数として定義するので,これらの文字は他の目的には使えなくなってしまうからである.
解答
|
#include <iostream>
using namespace std; int main() { enum Answer {NO=0, YES=1}; int answer; cout << "C++は好きですか?\n << "答えがYESなら1を,NOなら0でお答えください" << endl; cin >> answer; if(answer == YES){ cout << "C++は好きですね" << endl; } else { cout << "C++は嫌いですか" << endl; } } |
実行結果
![\begin{figure}% latex2html id marker 561
\centering\includegraphics[width=9.5cm]{CPPPIC/reidai2-7.eps}
\end{figure}](img26.png)
|
練習問題 2..6
列挙型
8進数の数を入力し,8,10, 16進数のどれかを選んで表示するプログラムを列挙型を用いて作成せよ.8進数の入力には,cin  oct nを用いる.また,10進の入力にはcin dec nを用いる.ただし,入力する数の先頭に0を付ける. oct nを用いる.また,10進の入力にはcin dec nを用いる.ただし,入力する数の先頭に0を付ける. |
ここからは,基本形ではないのでC++がはじめてのプログラミング言語の人は,さっと読んでおくだけでよい.6章から9章で詳しく取り扱う.
基本型から派生した「配列」という型がある.配列の宣言は
|
[記憶クラス] データ型 配列名 [要素数]
|
例えば,int args[5]と書くとargsという配列名は配列型であることを意味し,args[0], args[1], args[2], args[3], args[4]がその要素を表す.配列の要素の番号は0から始まるので,要素数が5ということは0から4までとなる.
解答
|
int prime[ ] = {2,3,5,7,11,13,17}
|
解答
|
#include <iostream>
using namespace std; int main () { int prime[] = {2,3,5,7,11,13}; int k = prime[4]; cout << "prime[4]=" << k << "です\n"; } |
 でつなげることができる.配列は0から始まるのでprime[4]が5番目の11となる.
でつなげることができる.配列は0から始まるのでprime[4]が5番目の11となる.
実行結果
![\begin{figure}% latex2html id marker 592
\centering\includegraphics[width=9.0cm]{CPPPIC/reidai2-9.eps}
\end{figure}](img27.png)
|
練習問題 2..7
配列の要素
{0,1,1,2,3,5,8,13,21,34}を要素とする配列aを定義し,第3番目と4番目の要素の和を求めるプログラムを作成せよ. |
| H | e | l | l | o |  0 0 |
文字配列型とは,メモリ内でナル文字(日本ではヌル文字とよばれる) で終了している文字列で次のような特徴を持っている.
で終了している文字列で次のような特徴を持っている.
0'が付く.
str;
buffer;
システムは空白文字にぶつかるまで,cinからbufferに文字をコピーする.
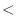 cstring
cstring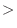 で宣言された関数は,文字配列を操作するのに用いることができる.これらの関数には,文字列の長さを求めるstrlen(),文字列の複写をするstrcpy()とstrncpy(),文字列を連結するstrcat()とstrncat(),文字列を比較するstrcmp()とstrncmp()などがある.
で宣言された関数は,文字配列を操作するのに用いることができる.これらの関数には,文字列の長さを求めるstrlen(),文字列の複写をするstrcpy()とstrncpy(),文字列を連結するstrcat()とstrncat(),文字列を比較するstrcmp()とstrncmp()などがある.
|
練習問題 2..8
文字列の文字配列への格納
文字配列を用いて,自分の名前(漢字)をキーボードから入力し,こんにちはだれだれさんと表示するプログラムを作成せよ.char name[20]で文字を入れる配列が定義できる.cin nameでキーボードから入力した名前を配列nameに格納できる. |
解答 文字列の文字配列への格納にはポインタを用いる.詳しくは8章で学ぶので,この段階ではさっと目を通しておけばよい.
|
#include <iostream>
using namespace std; int main () { char* weekDays [] = {"日曜","月曜","火曜","水曜","木曜","金曜","土曜"}; char* s = weekDays[2]; cout << "weekDays[2]=" << s << "です\n"; } |
実行結果
![\begin{figure}% latex2html id marker 646
\centering\includegraphics[width=9.0cm]{CPPPIC/reidai2-10.eps}
\end{figure}](img29.png)
解説 char* weekDays [] = {"日曜","月曜","火曜","水曜","木曜","金曜","土曜"};で
weekDays[0]="日曜"
weekDays[1]="月曜"
……
weekDays[6]="土曜"
と7つの変数が定義される.次に
char* s = weekDays[2];で文字列 "火曜" がsに代入される.
1文字以上の文字列を表す「文字列型」はオブジェクト扱いになる.標準のC++ 「string型」はstringのヘッダファイルで定義されている.「string型」のオブジェクトはいろいろな形で宣言されたり初期化される.詳しくは9章で学ぶ.
| string s1; | // s1は零個の文字を含んでいる. |
| string s2 = "New York"; | // s2は8個の文字を含んでいる. |
| string s3(60, '*'); | // s3は60個のアスタリスクを含んでいる. |
| string s4 = s3; | // s4は60個のアスタリスクを含んでいる. |
| string s5(s2,4,2); | // s5は2文字"Yo"を含んでいる. |
もし,文字列がs1のように初期化されなければ,1文字も含まないstringとなる. 文字列は,s2のように文字配列と同じように初期化することができる.s5(s2,4,2)は3つのパーツを持っている. 親の文字列(s2,here),文字の開始(s2[4],here),そして部分文字の長さ(2,here).
文字列型では文字を取り込むgetline()関数が文字配列型のcin.getline()と同じように使える.
解答
|
#include <iostream>
#include <string> using namespace std; int main () { string s1; string s2 = "New York"; string s3(60,'*'); string s4 = s3; string s5(s2,4,2); cout << s2 << "\n" << s3 <<< "\n" << s4 << "\n" << s5 << endl; } |
実行結果
![\begin{figure}% latex2html id marker 667
\centering\includegraphics[width=9.0cm]{CPPPIC/reidai2-11.eps}
\end{figure}](img30.png)
|
練習問題 2..9
文字列の操作
文字列を用いて,自分の名前(漢字)をキーボードから入力し,こんにちはだれだれさんと表示するプログラムを作成せよ.また,文字列を扱うにはstringの方が配列より優れていることを実感せよ. |
コンピュータのレジスタが有限桁数で演算をおこなうため,レジスタに入りきらない数値があると無視されたりして,演算結果と真の値に違いが出る.このような違いを誤差(Error)という.
ほとんどのマシンでは,long int 型は4バイトつまり,32ビットの領域が与えれている.しかし,これを超えるような計算をやらせると,間違った結果を表示する.これをオーバーフロー(overflow)という.
データ型で許されている最小値より小さい絶対値を持つ値が代入され,零になることをアンダーフロー(underflow)という.
例えば,有理数1/3をコンピュータは0.333333としてメモリにしまう.このとき生まれる誤差をラウンドオフ エラーまたはまるめ誤差(round-off error)という.
|
#include <iostream>"
>
using namespace std; int main() { double x = 1000/3.0; double y = x - 333.0; double z = 3*y -1.0; if (z == 0) cout << "z == 0\"; else cout << "z != 0\"; } |
解答 このプログラムを実行すると,z != 0が表示される.紙の上での計算ではz=0のはずがコンピュータではz!=0になる.つまり,まるめ誤差のため,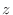 は0とはならない.つまり,プログラムで値が零なのかテストするには,z == 0ではなく,
は0とはならない.つまり,プログラムで値が零なのかテストするには,z == 0ではなく,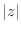 10E-20などでテストしよう.したがって,1点でのテストは控えるようにしよう.条件文については次の章で説明する.
10E-20などでテストしよう.したがって,1点でのテストは控えるようにしよう.条件文については次の章で説明する.
実行結果
![\begin{figure}% latex2html id marker 703
\centering
\includegraphics[width=8.0cm]{CPPPIC/reidai2-12.eps}
\end{figure}](img33.png)
|
練習問題 2..10
まるめ誤差
次のプログラムを実行し,まるめ誤差がどこに潜んでいるのか見つけよ. |
#include iostream
using namespace std;
int main ()
{
double x = 1/9.0;
double y = 1/11.0;
double z = x - y;
double w = 99*z;
cout w endl;
if(w == 2) cout "w = 2";
else cout "w != 2" endl;
}
ほぼ等しい数値どうしの引き算,絶対値がほぼ等しく符号が異なる2数の加算などを行った場合,有効桁数が急激に減少することがある.このような現象をけた落ち(cancelling in digits)という.
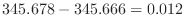
大きな値と小さな値の加減算を行った場合に,小さい値のけたを大きな値のけたにそろえることによって,仮数部に入りきらない小さい値の情報の一部が落ちてしまうことがある.このような現象を情報落ちという.
スコープ(scope) 宣言を行うことにより識別子は使えるようになる.このとき,識別子はプログラムテキストの特定部分でしか使えない.例えば,関数内で宣言された識別子の場合は,スコープは,宣言の位置から宣言が行われたブロックの末尾までである.ここで,ブロック(block)とは,{ }で区切られた部分である.
1. countが100を超えたら,"多すぎます" と表示する文を1行で書きなさい.
2. 次のプログラムの間違いを見つけよ.
|
#include <iostream>
using namespace std; int main() { cout << "nを入力して下さい:"; cin >> n; if(n < 0) cout << "負の値です.もう一度nを入力して下さい." << endl; cin >> n; else cout << "O.K. n = " << n << endl; } |
3. 次のコードのどこが間違っているか見つけよ.
enum Semester {FALL, SPRING, SUMMER};
enum Season {SPRING, SUMMER, FALL, WINTER};
4. 次の式の値を求めよ.ただし,mの値は25,nの値は7とする.
a. m - 8 - n
b. m = n = 3
c. m%n
d. m%n++
e. m%++n
f. ++m - n$--$
5. nから1を引くというコードを4つの方法で表せ.
6. どこが間違っているか.
a. cin count;
b. if (x y) min = x
else min = y;
1. 次のプログラムの実行結果がどうなるか考えよ.
|
#include <iostream>
int namespace std; int main () { char c = 'A'; int i; int j = 0x41; cout << "\nc=" << c; i = (int)c; cout << "\nc=" << i; cout << "\nj=" << j; i= 66; cout << "\ni=" << i; c=(char)i; cout << "\n$c=" << c << endl; } |
2. 10個の大文字の母音と小文字の母音を表示するプログラムを例題2.2をまねて作成せよ.