Next: クラス(class) Up: C++プログラミング入門 Previous: 文字配列型(C-Strings) 目次 索引
前節で学んだ文字配列はC++の中の重要な部分である.文字配列はデータの編集に効率のよい道具を提供してくれる.ただ,この効率の良さは,ナル文字を用いていることによる動作誤差というリスクを背負っている.
そこで,C++には標準C++ストリング(standard C++ strings)とよばれ,文字配列に代わる動作誤差の少ないものがある.文字列の長さを文字列の中に含ませることにより,ナル文字に頼る必要を無くしたものである.
書式付入力(Formatted Inputs)
C++での入力はistreamオブジェクトcinを通り,出力はostreamオブジェクトcoutを通る.istreamクラスはcinのようなオブジェクトの行動を定義する.最も顕著な行動は抽出演算子(extraction operator)(または入力演算子) の使い方であろう.抽出演算子はistreamオブジェクトから文字を抽出し,それらの文字に対応する値をオブジェクトに複写する.入力された文字から対応する値を形成するこの過程をフォーマットという.
の使い方であろう.抽出演算子はistreamオブジェクトから文字を抽出し,それらの文字に対応する値をオブジェクトに複写する.入力された文字から対応する値を形成するこの過程をフォーマットという.
n;
解答 入力された数字46は実際は7つの文字' ' , ' ' , ' ' ,' ' ,'4' , '6' ,'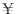 n'を含んでいる.つまり4つの空白と数字4,6そして改行文字である.これは下の図のように考えることができる.
n'を含んでいる.つまり4つの空白と数字4,6そして改行文字である.これは下の図のように考えることができる.
![¥begin{figure}¥centering
¥includegraphics[width=11.2cm]{CPPPIC/fig9-1.eps}
¥end{figure}](img236.png)
ストリームオブジェクトcinは一度にひとつずつ文字をスキャンする.もし,最初にスキャンした文字が余白文字(whitespace)(空白文字, タブ, 改行文字, etc)ならばそれを取り込み,無視する.そして,次の文字のスキャンを始める.この取り込んで無視するという作業を余白文字以外をスキャンするまで繰り返す.cin nは整数型を持っているので,オブジェクトcinは整数型を探す.つまり,余白文字を全て取り除いたら,'+', '-', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9'の12文字のどれかをスキャンすることを待っている.
もしこれ以外の244文字の中のどれかに出会うと,その文字をストリームに残してスキャンをストップする.この例題の場合,'4'をスキャンし取り込み,次も整数が出ることを期待している.次の'6'をスキャンし取り込み,その次に数字以外をスキャンすると,スキャンした文字を残しストップする.よって,この場合,cinは4つの空白,'4', '6'の6文字を抽出し,空白は除去し,'4'と'6'をくっつけて整数値46を作る.そして,その値をオブジェクトnにコピーする.この抽出がすんだ後,改行文字'n'はまだ入力ストリームに残されていて,次の入力が別の書式付入力ならば,空白文字と同様に改行文字は無視される.
抽出演算子 は入力ストリームを通るデータをフォーマットする.つまり,ストリームから文字を抽出し,それを用いて2つ目の演算子と同じ型の値にする.この過程で,空白文字はすべて無視される.この結果,抽出演算子を用いて空白文字を読むことはできない.よって,空白文字を読まなければならない場合は,cinメンバ関数の1つであるcin.get( )のようなフォーマットされない入力関数を用いる必要がある.
|
#include <iostream>
using namespace std; int main( ) { int n; while(cin >> n){ cout << "n = " << n << endl; } } |
| 抽出文字が整数型を返すかぎりループは続く. |
実行結果
![¥begin{figure}% latex2html id marker 2974
¥centering
¥includegraphics[width=7.8cm]{CPPPIC/reidai9-2.eps}
¥end{figure}](img237.png)
|
練習問題 9..1 上の例題でint n;をchar n;に変更するとどんな結果が得られるか.
|
書式付でない入力(Unformatted Inputs)
 iostream
iostream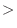 には余白文字を無視しない関数がいくつかある.よく使われるのはcinのメンバ関数であるcin.get( )とcin.getline( )である.cin.get( )は文字配列から一文字ずつ読み,cin.getline( )は文字配列から一行ずつ読む.
には余白文字を無視しない関数がいくつかある.よく使われるのはcinのメンバ関数であるcin.get( )とcin.getline( )である.cin.get( )は文字配列から一文字ずつ読み,cin.getline( )は文字配列から一行ずつ読む.
例えば,上の例題で34,45,56を読み込みそのまま表示したい場合は,
char c;
while (cin.get(c))
{
cout.put(c);
}
とすればよい.
|
練習問題 9..2 34, 45, 56と入力し,
34, 45, 56 と表示するプログラムを作成せよ. |
標準文字列型(Standard C++String Types)
1文字以上の文字列を表す「文字列型」はオブジェクト扱いになる.標準のC++ 「string型」はstringのヘッダファイルで定義されている.「string型」のオブジェクトはいろいろな形で宣言されたり初期化される.
| string s1; | // s1は零個の文字を含んでいる. |
| string s2 = "New York"; | // s2は8個の文字を含んでいる. |
| string s3(60, '*'); | // s3は60個のアスタリスクを含んでいる. |
| string s4 = s3; | // s4は60個のアスタリスクを含んでいる. |
| string s5(s2,4,2); | // s5は2文字"Yo"を含んでいる. |
もし,文字列がs1のように初期化されなければ,1文字も含まないstringとなる. 文字列は,s2のように文字配列と同じように初期化することができる. また,文字列は初期化後,s3のように指定された数だけ文字を格納することができる.文字配列との違いは,文字列ではs3のように別のオブジェクトのコピーを用いて初期化することができることである.s5(s2,4,2)は3つのパーツを持っている. 親の文字列(s2,here),文字の開始(s2[4],here),そして部分文字の長さ(2,here)である.
フォーマットされた入力は文字配列型と同じように文字列型でも使うことができる.
文字列型では文字を取り込むgetline()関数が文字配列型のcin.getline()と同じように使える.
| string s = "ABCEFG"; |
| getline(cin,s); // 一行全部を読んでsに入れる. |
| char c = s[2]; // 文字'C'をcに代入 |
| s[4] = '*'; // 文字列sを"ABCD*FG"に変更 |
| const char* cs = s.c_str( ); // 文字列sを文字配列csに変換する. |
| c_str( )関数はconst char*型を持っている. |
| cout << s.length( ) << endl; // 文字列sの文字数7を表示する. |
| c_str( )関数はconst char*型を持っている. |
| if(s2 < s5) cout << "s2は辞書の順でs5より前である.¥n"; |
| string s6 = s + "HIJK"; // s6をEFを消去し"ABCD*FGHIJK"に変更 |
| s2 += s5; // s2のHIをxyzで置き換え"New YorkYo"に変更 |
| s4 = s6.substr(5,3); // s4を"FGH"に変更 |
| s6.erase(4,2); // s6を"ABCDGHIJK"に変更 |
| s6.replace(5,2,"xyz"); // s6を"ABCDGxyzJK"に変更 |
| string s7 = "Mississippi River"; |
| cout << s7.find("si") << endl; // 3を表示 |
| cout << s7.find("so") << endl; // 文字列の長さ17を表示 |
cout 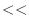 s7.find("so") endl; // 文字列の長さ17を表示 s7.find("so") endl; // 文字列の長さ17を表示 |
解答 tを見つけるには,find()関数を用いることができる.find()関数は見つかった文字が格納されている位置を返す.次に,tの後が母音かを判断しなくてはいけない.そこで,is_vowel()関数を作成する.is_vowel()関数は,母音かどうかを判断する関数なので,
bool is_vowel(char c)
{
return (c =='a' 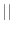 c== 'e' c == 'i' c == 'o' c == 'u');
c== 'e' c == 'i' c == 'o' c == 'u');
}
と書けばよい.
では,プログラムを作成しよう.
|
#include <iostream>
#include <string> bool is_vowel(char); using namespace std; int main() { string word; int k; while(cin >> word) { k = word.find("t"); if(k < word.length() && is_vowel(word[k+1])) { word.replace(k+1,0,"eg"); } cout << word << ' '; } } bool is_vowel(char c) { return (c =='a' || c== 'e' || c == 'i' || c == 'o' || c == 'u'); } |
実行結果
![¥begin{figure}% latex2html id marker 3025
¥centering
¥includegraphics[width=15.15cm]{CPPPIC/reidai9-3.eps}
¥end{figure}](img238.png)
ファイル(Files)
C++におけるファイル処理は標準入出力とよく似ている.ファイルからの入力は,キーボードからの入力をistreamオブジェクト
であるcinが管理するようにifstreamオブジェクト
により管理されている.同様に,ファイルへの出力は,ディスプレイへの出力をostreamオブジェクト
であるcoutが管理するように,ofstream
により管理される.唯一の違いはifstreamとofstreamオブジェクトは明示的に宣言され,外部名を用いて初期化されなければならないことである.また,ヘッダファイルfstream(またはANSIC++以前ではfstream.h)をインクルードしなければならない.
解答 それぞれの語の先頭を大文字に変更するプログラムを書けばよい.小文字を大文字に変更するには,小文字と大文字のASCIIコードでの差'A' - 'a'を変更したい文字に足せばよい.ファイルの読み込みと書き込みは
|
ifstream infile("input.txt");
ofstream outfile("output.txt"); |
|
#include <fstream>
#include <iostream> #include <string> using namespace std; int main() { ifstream infile("input.txt"); ofstream outfile("output.txt"); string word; char c; while(infile >> word){ if (word[0] <= 'a' && word[0] <= 'z') { word[0] += 'A' - 'a'; } outfile << word; infile.get(c); outfile.put(c); } } |
実行結果
![¥begin{figure}% latex2html id marker 3045
¥centering
¥includegraphics[width=17cm]{CPPPIC/reidai9-4.eps}
¥end{figure}](img239.png)
この処理方法を図で表すと
![¥begin{figure}¥centering
¥includegraphics[width=12.9cm]{CPPPIC/fig9-4.eps}
¥end{figure}](img240.png)
|
練習問題 9..3
上の例題において,小文字から大文字への変換をword[0] += 'A' - 'a'で行なったが,toupper()関数を変わりに用いてプログラムを実行せよ.
|
コマンドラインからのリダイレクションを用いずに,外部ファイルを用いることの利点は,1つのプログラムに用いることのできるファイルの数に制限がないことである.
文字列ストリーム(String Streams)
文字列ストリームは,ファイルを用いて文字列を扱う代わりに,メモリ内でテキストを扱うかのように文字列の使用を許すストリームオブジェクトであり,メモリ内I/Oともよばれる.
したがって,文字列ストリームは入力と出力のバッファに非常に役に立つ.文字列ストリームの型istringstreamとostringstreamはヘッダファイルsstreamに定義されているので,これらを用いるときには,sstreamをインクルードする必要がある.
![¥begin{figure}¥centering
¥includegraphics[width=7.6cm]{CPPPIC/fig9-2.eps}
¥vspace{-0.8cm}
¥end{figure}](img241.png)
|
#include <iostream>
#include <sstream> #include <string> using namespace std; void print(ostringstream&); int main() { string s="ABCDEFG"; int n=33; double x=2.718; ostringstream oss; print(oss); oss << s; print(oss); oss << " " << n; print(oss); oss << " " << x; print(oss); } void print(ostringstream& oss) { cout << "oss.str() = ¥"" << oss.str() << "¥"" << endl; } |
解答 最初にprint(oss)が呼ばれたときには,ossにはまだ何も挿入されていない.次にprint(oss)が呼ばれたときには,ossには文字列"ABCDEFG"が読み込まれている.その次にprint(oss)が呼ばれたときには,空白とnの値33が読み込まれている.最後にprint(oss)が呼ばれたときには,ossにはさらに空白とxの値2.718も読み込まれている.
実行結果
![¥begin{figure}% latex2html id marker 3080
¥centering
¥includegraphics[width=8.45cm]{CPPPIC/reidai9-5.eps}
¥end{figure}](img242.png)
出力文字列ストリームオブジェクトossは出力ストリームcoutのような働きをする.つまり,文字列sの値,整数nの値,実数xの値は挿入演算子によって,ossに書き込まれる.言い換えると,内部オブジェクトであるossが外部テキストファイルのような働きをしている.このとき,内部オブジェクトossの中身はoss.str()によってアクセスできる.
![¥begin{figure}¥centering
¥includegraphics[width=7.6cm]{CPPPIC/fig9-3.eps}
¥end{figure}](img243.png)
解答 入力文字列ストリームオブジェクトissは入力ストリームcinのような働きをする.つまり,文字列sの値,整数nの値,実数xの値が抽出演算子によって,issから読み込まれる.このとき,内部オブジェクトであるissは外部テキストファイルのような働きをしている.つまり,内部オブジェクトissの中身は読み込みによっては変化しない.
|
#include <ostream>
#include <sstream> #include <string> using namespace std; void print(string&, int, float, istringstream&); int main() { string s; int n=0; double x=0.0; istringstream iss("ABCDEFG 44 3.14"); print(s,n,x,iss); iss >> s; print(s,n,x,iss); iss >> n; print(s,n,x,iss); iss >> x; print(s,n,x,iss); } void print(string& s, int n, float x, istringstream& iss) { cout << "s = ¥"" << s << "¥", n = " << n << ", x = " << x << ", iss.str() = ¥"" << iss.str() << "¥"" << endl; } |
実行結果
![¥begin{figure}% latex2html id marker 3099
¥centering
¥includegraphics[width=14.05cm]{CPPPIC/reidai9-6.eps}
¥end{figure}](img244.png)
|
練習問題 9..4 次のコードを以下の入力に対して実行すると,どんな結果が得られるか.
a. ABC 456 7.89 XYZ b. ABC 4567 .89 XYZ c. ABC 456 7.8 9XYZ d. ABC456 7.8 9 XYZ e. ABC456 7 .89 XYZ f. ABC4 56 7.89XY Z g. AB C456 7.89 XYZ h. AB C 456 7.89XYZ |
| #include <iostream>
#include <fstream> using namespace std; bool more(ifstream& fin, int& n) { if (fin >> n) return true; else return false; } bool copy(ofstream& fout, ifstream& fin, int& n) { fout << " " << n; return more(fin,n); } int main() { ifstream fin1("north.dat"); ifstream fin2("south.dat"); ofstream fout("combined.dat"); int n1,n2; bool more1 = more(fin1, n1); bool more2 = more(fin2, n2); while(more1 && more2) if(n1 < n2) more1 = copy(fout, fin1, n1); else more2 = copy(fout, fin2, n2); while(more1) more1 = copy(fout, fin1, n1); while(more2) more2 = copy(fout, fin2, n2); fout << endl; } |
| north.dat | |||||||
| 27 | 35 | 48 | 52 | 55 | 61 | 81 | 87 |
| south.dat | |||||||||
| 31 | 34 | 41 | 45 | 49 | 56 | 63 | 74 | 92 | 95 |
とすると,
実行結果
![¥begin{figure}% latex2html id marker 3123
¥centering¥includegraphics[width=12.5cm]{CPPPIC/reidai9-7.eps}
¥end{figure}](img245.png)
1. 文字配列とC++文字列の違いを述べよ.
2. 書式付入力と書式付でない入力の違いを述べよ.
3. 抽出演算子ではなぜ余白文字を読むことができないのか.
4. ストリームとはなにか.
5. C++ではどのようにして文字列,外部ファイル,内部ファイルの処理を簡単にしているか.
6. read()関数とwrite()関数は何を行なうか述べよ.
1. 次のコードは何を行なうか述べよ.
char cs1[] = "ABCDEFGHIJ";
char cs2[] = "ABCDEFGH";
cout cs2 endl;
cout strlen(cs2) endl;
cs2[4] = 'X';
if (strcmp(cs1,cs2) 0) cout cs1 " " cs2 endl;
else cout cs1 "  " cs2 endl;
" cs2 endl;
char buffer[80];
strcpy(buffer, cs1);
strcat(buffer, cs2);
char* cs3 = strchr(buffer, 'G');
cout cs3 endl;
2. 行数,単語数,文字の出現数を数えて表示するプログラムを作成せよ.