Next: 標本の散布度,相関関係(sample dispersion, correlation) Up: 資料の整理 Previous: 資料の整理 目次 索引
サンプリング
データの収集過程やサイコロを投げるなどの試行を繰り返すことにより結果を得る過程をサンプリング(sampling)といいます.サンプリングの結果えられたものをサンプル(sample)または標本といいます.
例えば,次のようなデータを得たとしましょう.
このデータを見ただけでは,どんな結果がでたのか分かりにくいので,これらのデータを整理して分かりやすい表にすることを考えます.データの整理の方法として度数分布表(frequency table)を用いることがよくありますので,度数分布表の作り方を学びます.
データの値を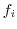 で表すとき,が現れる回数を度数(frequency)といい,
で表すとき,が現れる回数を度数(frequency)といい,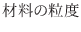 で表すと,
で表すと,
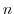
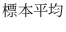 はデータの数です.これより,度数を表にしたものを作成することができます.
はデータの数です.これより,度数を表にしたものを作成することができます.
| 可能な値 | 度数 |
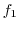 |
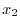 |
 |
 |
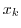 |
|
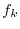 |
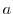 |
| 合計 | n |
しかし,データの多くは小数点以下を切り捨てたり,四捨五入したりして得たものなので,という値で表を作成する代わりに,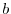 以上
以上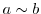 未満での度数という形で表を作成します.このとき,データを以上未満というようないくつかの区間に分けて集計するときの各区間を階級(class interval)といい,
未満での度数という形で表を作成します.このとき,データを以上未満というようないくつかの区間に分けて集計するときの各区間を階級(class interval)といい,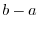 で表します.そして, 区間の幅つまり
で表します.そして, 区間の幅つまり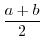 を階級幅(class interval width)といいます.それぞれの区間の端点の相加平均
を階級幅(class interval width)といいます.それぞれの区間の端点の相加平均
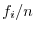 を階級値(midpoint)といいます.また,全標本の個数に対する各階級の度数の割合
を階級値(midpoint)といいます.また,全標本の個数に対する各階級の度数の割合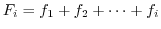 を相対度数(relative frequency)いいます.
さらに,統計解析のために以下の度数の合計
を相対度数(relative frequency)いいます.
さらに,統計解析のために以下の度数の合計
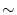
度数分布表を図(棒グラフ)で表したものをヒストグラム(histogram) といいます.また,変量の小さい階級から順に度数を加えていったものを累積度数(cumulative distribution function) といいます.
Sturgesの式
データ数に対して階級数を決める一つの目安にスタージスの式があります.
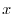 が50より,階級数
が50より,階級数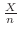 は
は
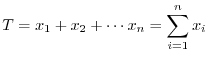
標本の代表値
度数分布表が得られると,データ全体を視覚的に把握することができるようになります.しかしながら,それはあくまで直感的なことです.そこで,直感に頼るのではなく理論的にデータを処理するために,データの特徴を数値で表します.
代表値 : 分布の特徴を代表する数値
変量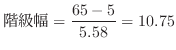 に関する個のデータ
に関する個のデータ
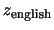 が与えられたとき,
が与えられたとき,
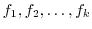
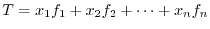 の値が
の値が
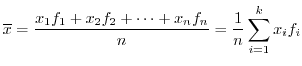 で,その度数が
で,その度数が
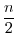 で与えられているとき,標本総計値は
で与えられているとき,標本総計値は
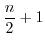
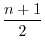
変量の測定値を,大きさの順に並べたとき,中央の位置にくるものを,ミディアン(median)または中央値といいます.データの数が偶数のときは第
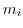 番目と第
番目と第
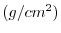 番目の変量の平均が中央値.また,データの数が奇数のときは第
番目の変量の平均が中央値.また,データの数が奇数のときは第
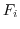 番目の変量が中央値となります.
番目の変量が中央値となります.
度数が最も大きい標本値,または階級値 をモード(mode)または最頻値といいます.
をモード(mode)または最頻値といいます.
|
|
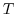
| 320 | 380 | 340 | 410 | 380 | 340 | 360 | 350 | 320 | 370 |
| 350 | 340 | 350 | 360 | 370 | 350 | 380 | 370 | 300 | 420 |
| 370 | 390 | 390 | 440 | 330 | 390 | 330 | 360 | 400 | 370 |
| 320 | 350 | 360 | 340 | 340 | 350 | 350 | 390 | 380 | 340 |
| 400 | 360 | 350 | 390 | 400 | 350 | 360 | 340 | 370 | 420 |
| 420 | 400 | 350 | 370 | 330 | 320 | 390 | 380 | 400 | 370 |
| 390 | 330 | 360 | 380 | 350 | 330 | 360 | 300 | 360 | 360 |
| 360 | 390 | 350 | 370 | 370 | 350 | 390 | 370 | 370 | 340 |
| 370 | 400 | 360 | 350 | 380 | 380 | 360 | 340 | 330 | 370 |
| 340 | 360 | 390 | 400 | 370 | 410 | 360 | 400 | 340 | 360 |
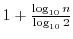
![\includegraphics[width=6cm]{STATFIG/rei1-1.eps}](img22.png)
![\includegraphics[width=6cm]{STATFIG/rei1-2.eps}](img23.png)